随机过程 第一章 预备知识(1)
1、看图重识条件概率:
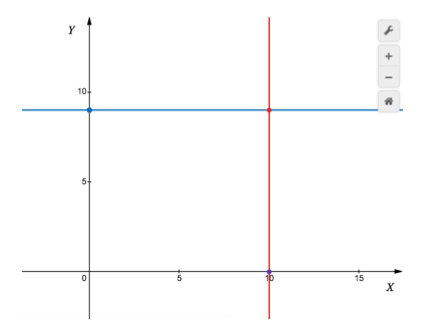
对应图上Y=y的直线,因直线的连续性,用连续随机变量的写法进行分析。(P(Y)是离散随机变量的记法)
:即线的边缘概率密度乘上此线条在一个极小(无穷小)的宽度的值。
概率密度:描述单位长度的“概率浓度”, 而单个点勒贝格测度(长度)为0,所以单点的概率都是0。因此给一个极小的距离代表此点的长度,因此概率=概率密度*长度(面积),相对应于物理中,也就有概率质量之说。
因在二维空间内,在图中是一条直线,所以其概率密度是包含了所有的x情况下,称为边缘概率密度:,此对应是图上点的概率密度,把所有的x都加上后,x变量不再存在,剩下的就是y的一个函数。
所以条件概率对应图中是已知出现在Y=y线上时,出现在X=x的点概率,很自然是出现在Y=y线的值(概率)分之出现在X=x点的值(概率)
,图中全部点的概率之和等于1
为此我们自己可以出题,如图中,中间的全部概率之和需等于1,
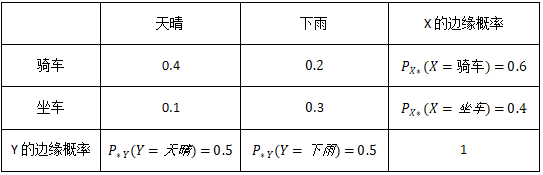
那假设:X设为出行是骑车还是坐车,Y设为天气是天晴或是下雨;
则边缘概率有:X为坐车情况的边缘概率(包含下雨和天晴的之和),骑车情况同理;Y为天晴的边缘概率(包含骑车和坐车的之和),下雨情况同理。
2、条件期望的期望等于期望:
期望等于变量取值的平均值,即全部取值乘以其对应概率的和:或离散形式
,其中条件期望中变量取值:已知在发生条件Y的情况下取x值的情况,那变量取值就是x了;再乘上条件概率即是条件期望的公式。此表达式运算完,x全部的取值都计算过了,不再是变量;则是对的值在Y为变量下取期望,即
后面两个概率的乘积获得是联合概率,
更换求和位置,
后面的求和即是边缘概率
利用此方式,对于单独求X期望比较难时,通过给定一些条件下,去把原来的情况做具体划分,然后统计每个划分下的概率,反而较容易求得。
把比较笼统的事件通过划分具体化,从而更好求得
如上面举例情况,需要求一段时间消耗的卡路里,如果不划分,则千头万绪;而通过划分,比如上面骑车消耗100卡路里、坐车消耗10卡路里情况下去求;当然上面的例子比较简单,划分越细则结果越准确。
3、协方差
通过上面的介绍,协方差为取值的期望,为好理解,可假设,因此是Z与Z出现的概率之积再求和,Z出现的概率为同时出现的联合概率。以连续变量为例:。
再看当(简单起见,假设均值都为0),可看出,即是与全部的y的积取其概率贡献值再求和,因此当某个出现的概率大时,值就会偏向其。如上面的例子,假设天晴为1,下雨为-1,则在骑车情况下,天晴出现的概率大,因此在天晴时消耗的卡路里大,整体值是偏大。而在坐车情况下,下雨时的概率大,整体就是把小的往更小的方向偏(下雨为-1,所以负数往更小方向)。在此时就一定要出现均值进行计算了,不然像上面例子消耗卡路里骑车100、坐车消耗10,加上后并不能直观看出什么。而后,骑车情况45,坐车是-45,骑车在天晴情况下概率大,所以是正数,而坐车-45在下雨时的概率大,与-1相乘负负得正,也是正数,两者相加变得更大。这就说明天气和卡路里消耗是有关系的,而且是正相关。而把条件改一下,不是消耗卡路里,而是体重增加,则骑车肯定是增加的少,坐车增加的多,减均值就是骑车是负数,坐车是正数,计算后,就是一个负的值,此即为负相关。如果条件改成是另一个和你无关的人的消耗卡路里,当数据量很多时,计算结果将趋向于0,也即两个变量是相互独立的,不受影响。
4、相关系数:表示X、Y之间线性相关程度的大小
因为协方差计算会受到量纲影响,方差大的比方差小的协方差大,比如以元为单位就比以万元为单位的协方差大。而通过把变量标准化为均值为0,方差为1的变量,如:,则可消除量纲的影响。
而相关系数能限定值在[-1,1]:由柯西-施瓦茨不等式可知:
柯西-施瓦茨不等式:两个变量乘积的期望的平方,必然小于或等于这两个变量各自期望平方的乘积。
证明方法:令。此时,U 和 V 的期望均为 0。构造函数
,此式恒大于0则:
移项后,即
此时,相关系数反映的不再是原始数值的共变大小,而是两个变量在变化趋势上的形状相似度。它衡量的是两个变量每单位变化时的协同程度,而非受各自波动剧烈程度的影响。 通过除以标准差进行标准化,相关系数的取值被固定在-1到1之间。 1:表示完全正(线性)相关,即一个变量增加多少,另一个变量也按固定比例增加;如。 -1:表示完全负相关,即一个变量增加,另一个按固定比例减少。 0:表示无线性相关关系。